That’s an interesting question, and I try to answer this is a very general way. The tl;dr version of this is: Deep learning is essentially a set of techniques that help we to parameterize deep neural network structures, neural networks with many, many layers and parameters.
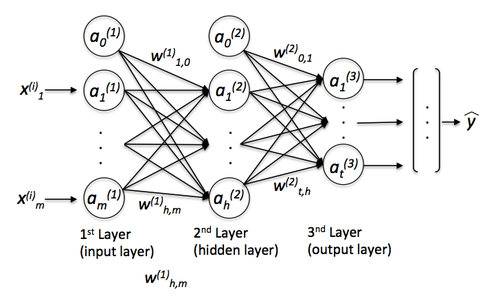
And if we are interested, a more concrete example: Let’s start with multi-layer perceptrons (MLPs) …
On a tangent: The term “perceptron” in MLPs may be a bit confusing since we don’t really want only linear neurons in our network. Using MLPs, we want to learn complex functions to solve non-linear problems. Thus, our network is conventionally composed of one or multiple “hidden” layers that connect the input and output layer. Those hidden layers normally have some sort of sigmoid activation function (log-sigmoid or the hyperbolic tangent etc.). For example, think of a log-sigmoid unit in our network as a logistic regression unit that returns continuous values outputs in the range 0-1. A simple MLP could look like this