curl https://sh.rustup.rs -sSf | sh
rustup update stable
Source: Announcing Rust 1.20 – The Rust Programming Language Blog
curl https://sh.rustup.rs -sSf | sh
rustup update stable
Source: Announcing Rust 1.20 – The Rust Programming Language Blog
Source: Documentation and Analysis of the Linux Random Number Generator – LinuxRNG_EN.pdf
This paper is about the development of the C programming language, the influences on it, and the conditions under which it was created. For the sake of brevity, I omit full descriptions of C itself, its parent B [Johnson 73] and its grandparent BCPL [Richards 79], and instead concentrate on characteristic elements of each language and how they evolved.C came into being in the years 1969-1973, in parallel with the early development of the Unix operating system; the most creative period occurred during 1972. Another spate of changes peaked between 1977 and 1979, when portability of the Unix system was being demonstrated. In the middle of this second period, the first widely available description of the language appeared: The C Programming Language, often called the `white book’ or `K&R’ [Kernighan 78]. Finally, in the middle 1980s, the language was officially standardized by the ANSI X3J11 committee, which made further changes. Until the early 1980s, although compilers existed for a variety of machine architectures and operating systems, the language was almost exclusively associated with Unix; more recently, its use has spread much more widely, and today it is among the languages most commonly used throughout the computer industry.
Source: Chistory
A year after calling advisory “false and misleading,” maker warns patients to patch.
Source: 465k patients told to visit doctor to patch critical pacemaker vulnerability | Ars Technica
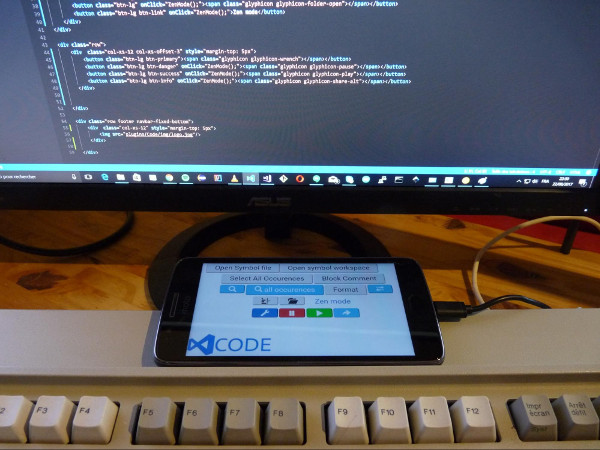
Put your smartphone on top of your keyboard and use it as a “shortcuts touchscreen device”.
Source: My smartphone as a shortcut helper
Why should you work in your PhD 24/7 till exhaustion if there is a more effective and efficient way?
Source: The Secret PhD Productivity Strategy: Do Deep Work In Less Hours
 Source: The software engineering rule of 3
Source: The software engineering rule of 3
 Source: Python Data Science Handbook | Python Data Science Handbook
Source: Python Data Science Handbook | Python Data Science Handbook
Should we ditch Python and other languages in favor of Julia for technical computing? That’s certainly a thought that comes to mind when one looks at the benchmarks on http
My take on this kind of cross language comparison is that the benchmarks should be defined by tasks to perform, then have language experts write the best code they can to perform these tasks. If the code is all written by one language team, then there is a risk that other languages aren’t used at best.
One thing the Julia team did right is to publish on github the code they used. In particular, the Python code can be found here.
A first look at this code confirms the bias I was afraid of. The code is written in a C style with heavy use of loops over arrays and lists. This is not the best way to use Python.
I won’t blame the Julia team, as I have been guilty of the exact same bias. But I learned the hard lesson: loops on arrays or lists should be avoided at almost any cost as they are really slow in Python, see Python is not C.
Given this bias towards C style, the interesting question (to me at least) is whether we can improve these benchmarks with a better use of Python and its tools?
Before I give the answer below, let me say that I am in no way trying to downplay Julia. It is certainly a language worth monitoring as it is further developed and improved. I just want to have a look at the Python side of things. Actually, I am using this as an excuse to explore various Python tools that can be used to make code run faster.
In what follows I use Python 3.5.1 with Anaconda on a Windows machine. The notebook containing the complete code for all benchmarks below is available on github and on nbviewer.
Comments on various social media make me add this: I am not writing any C code here: if you’re not convinced, then try to find any semicolon. All the tools used in this blog run in the standard CPython implementation available in Anaconda or other distributions. All the code below runs in a single notebook. I tried to use the Julia micro performance file from github but it does not run as is with Julia 0.4.2. I had to edit it and replace @timeit by @time to make it run. I also had to add calls to the timed functions before timing them, otherwise the compilation time was included. I ran it with the Julia command line interface, on the same machine as the one used to run Python.
Source: How To Make Python Run As Fast As Julia (IT Best Kept Secret Is Optimization)

The menu crisis has been slow in coming — so slowly that few people are aware of it. Bit by bit, they have become accustomed to the inconvenience and distraction of the menu on the computer d…
Source: KDE and the Menu Crisis | OCS-Mag