In this guide, I will explain how to cluster a set of documents using Python. My motivating example is to identify the latent structures within the synopses of the top 100 films of all time (per an IMDB list). See the original post for a more detailed discussion on the example. This guide covers:
- tokenizing and stemming each synopsis
- transforming the corpus into vector space using [tf-idf](http://en.wikipedia.org/wiki/Tf%E2%80%93idf)
- calculating cosine distance between each document as a measure of similarity
- clustering the documents using the [k-means algorithm](http://en.wikipedia.org/wiki/K-means_clustering)
- using [multidimensional scaling](http://en.wikipedia.org/wiki/Multidimensional_scaling) to reduce dimensionality within the corpus
- plotting the clustering output using [matplotlib](http://matplotlib.org/) and [mpld3](http://mpld3.github.io/)
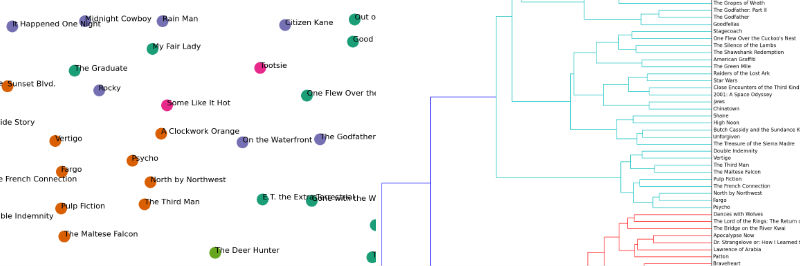
- conducting a hierarchical clustering on the corpus using [Ward clustering](http://en.wikipedia.org/wiki/Ward%27s_method)
- plotting a Ward dendrogram
- topic modeling using [Latent Dirichlet Allocation (LDA)](http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation)
http://nbviewer.ipython.org/github/brandomr/document_cluster/blob/master/cluster_analysis_web.ipynb